3. Algorithmes de recherche dans les systèmes à agents
3.2. Recherche informée distribuée
3.2.3. Recherche bidirectionnelle en temps réel (RTBS - Real
Time Bidirectional Search)
Une classe spéciale d`algorithmes de recherche en temps réel
concerne la recherche bidirectionnelle. C`est le cas de deux agents qui
effectuent des recherches dans le même espace d`états. On
a vu dans la section 3.1.4 que la recherche bidirectionnelle comprend
deux agents, un situé dans l`état initial et l`autre dans
l`état solution, qui déploient leur recherche un vers l`autre
et s`arrêtent quand leurs frontières de recherche s`intersectent.
On peut prendre comme exemple le cas de deux robots qui disposent de la
carte d'un labyrinthe et cherchent un chemin qui relie ces robots, l'un
situé à l'entrée et l'autre à la sortie du
labyrinthe. Dans la version off-line de la recherche bidirectionnelle,
les deux robots établissent en premier lieu un chemin entier tel
qu'ils se rencontrent et ensuite ils se mettent en mouvement.
Mais dans des situations dynamiques les deux robots peuvent ne pas se
rencontrer à cause d'événements imprévus.
Par exemple, un couloir du labyrinthe, qui fait partie du chemin d'un
robot, est bouché par un portion de mur détruit à
cause d'un mouvement mal contrôlé d'un robot. En ce cas,
pour ne pas avoir un échec, il faut que les robots s'arrêtent
et l'algorithme de recherche bidirectionnelle off-line recommence sa recherche
pour trouver des chemins pour les robots, dans la nouvelle configuration
du labyrinthe.
On peut observer que la méthode de recherche bidirectionnelle
off-line (trouver le chemin entier et ensuite donner les commandes de
déplacement) est plus co«teuse que la méthode de recherche
bidirectionnelle en temps réel (détermination à
chaque pas d`un simple mouvement suivante puis exécution de ce
mouvement). Il est évident que pour les situations dynamiques la
recherche en temps réel est plus appropriée.
Algorithme général RTBS
On a deux agents de recherche en temps réel qui tentent d`aller
un vers l`autre:
- Agent_Avant - un agent de recherche qui part de l`état
initial
- Agent_Arrière - un agent de recherche qui part d`un
des états solution
L`algorithme général de recherche bidirectionnelle
en temps réel exécute en boucle les pas suivantes:
- Stratégie de contrôle : sélectionne
un mouvement avant (aller en 2) ou arrière (aller en 3)
- Agent_Avant exécute un ¨mouvement avant£ ayant comme
cible l`Agent_Arrière
- Agent_Arrière exécute un ¨mouvement arrière£
vers sa cible - l`Agent_Avant
L'algorithme s'arrête quand les deux agents se rencontrent.
OOn distingue les classes suivantes d'algorithmes RTBS selon l'autonomie
accordée aux agents de recherche :
- centralisés la stratégie de contrôle évalue
toutes les possibilités de déplacement à chaque
pas et choisit le meilleur mouvement (avant ou arrière)
- découplés - la stratégie de contrôle assure
seulement le minimum contrôle nécessaire pour terminer
la recherche et laisse aux agents une grande autonomie de décision.
Pour les algorithmes RTBS centralisés les agents partagent
les valeurs des distances heuristiques et exécutent ensemble la
mise à jour des valeurs h(x,y) . Chacun des deux agents
de recherche peut être construit sur la base d`un algorithme LRTA*
ou RTA*.
Dans le cadre des algorithmes RTBS découplé, à
cause de l`autonomie des agents, l`information heuristique est distribuée.
Chaque agent de recherche assure la gestion de sa propre heuristique (h1(x,y)
pour l `Agent_Avant et h2(x,y) pour l`Agent_Arrière).
Même les valeurs initiales de h1(x,y) et h2(x,y)
peuvent être différentes parce qu`il n`est pas obligatoire
que les deux agents utilisent la même fonction heuristique. En
ce qui concerne l`algorithme utilisé pour les agents, il est évident
que chaque agent constitue une cible mouvante pour l`autre, donc on va
adopter pour chacun un algorithme de recherche de cible mouvante (Agent_MTS).
Recherche bidirectionnelle en temps réel centralisée
On considère trois agents : un qui réalise la stratégie
de contrôle et deux agents de recherche : Agent_Avant
et Agent_Arrière. On va désigner par x la position
de l `Agent_Avant et par y la position de l`Agent_Arrière.
Un algorithme général pour la classe des algorithmes RTBS
centralisés peut être décrit comme suit.
1. La stratégie de contrôle
tant que *)les deux agents ne se rencontrent pas faire
*) calculer H1 = (h(x`,y),x`)/ chacune x`dans Successeurs(x)}
Xproche = fonct_min(H1)
hXmin = h(Xproche,y)
*) calculer H2 = (h(x,y`),y`)/ chacune y` dans Successeurs(y)}
Yproche = fonct_min(H2)
hYmin = h(x,Yproche)
h(x,y) = min ( hXmin + co«t(x,Xproche), hYmin + co«t(y,Yproche))
si hXmin < hYmin alors
*) commande le mouvement de l`Agent_Avant
sinon
si hXmin < hYmin alors
*) commande le mouvement de l`Agent_Arrière
sinon
*) commande au hasard le mouvement de l`Agent_Avant
ou de l`Agent_Arrière
fin si
fin si
fin tant que
Selon l`algorithme utilisé, la fonction fonct_min retourne la
position pour laquelle on trouve :
- la valeur minimum de l`heuristique h dans le cas de LRTA*,
ou
- la deuxième (dans l'ordre croissant) valeur de l`heuristique
h dans le cas de RTA*.
En fonction de la position retournée par la fonction fonct_min()
on calcule les valeurs de l`heuristique pour les successeurs les plus
proches des agents de recherche: h(Xproche,y) et h(x,Yproche).
Dans la mise à jour de h(x,y), où x et y
les positions courantes des agents, on utilise la fonction co«t(a,b)
qui donne le co«t de l`arc (a,b). Dans beaucoup de problèmes
on peut considérer co«t(a,b)=1, "(a,b).
2. L`Agent_Avant
*) attend une commande de mouvement
*) exécute le déplacement en Xproche
x = Xproche
3. L`Agent_Arrière
*) attend une commande de mouvement
*) exécute le déplacement en Yproche
y = Yproche
Complétude
On peut prouver pour l`algorithme de recherche centralisée basé
sur LRTA* ou sur RTA* que si
- l`espace d`états est fini
- le graphe représentant l`espace d`états a des arcs ayant
des co«ts positifs
- il existe un chemin entre chaque nud et le nud solution
- les valeurs initiales de l`heuristique sont non-négatives et
admissibles
alors il est possible que les deux agents arrivent dans un même
état.
 Question.
Quelles sont les données partagées dans le cas de l`algorithme
centralisé de recherche bidirectionnelle en temps réel présenté ? Question.
Quelles sont les données partagées dans le cas de l`algorithme
centralisé de recherche bidirectionnelle en temps réel présenté ?
Algorithme découplé de recherche bidirectionnelle en temps
réel
Dans ce qui suit on va noter par x la position de l`agent courant (avant
ou arrière) et par y la position de l`autre agent. Les heuristiques
des deux agents seront notées par h1(x,y) pour
l `Agent_Avant et h2(x,y) pour l`Agent_Arrière
L`interaction des agents est décrite par l`échange des
messages à l`aide des fonctions suivantes :
- EnvoyerMsg(agent, type_message [,valeur]) envoie
à l`agent spécifié par le premier argument un message
de type précisé par le deuxième argument obligatoire,
message qui peut contenir éventuellement une valeur (si l`argument
optionnel n`est pas présent alors on envoie un message avec une
valeur nulle) ;
- Réception() met l`agent en attente jusqu'à ce qu'un
message arrive et retourne le message arrivé ;
- TypeMsg( message ) retourne le type de message ;
- ValeurMsg(message ) - retourne la valeur contenue dans le message.
En principe, on peut avoir trois types de messages :
- déplaces envoyé par la stratégie de
contrôle à l`agent qui va effectuer un mouvement
- maj_cible - envoyé par l`agent qui a effectué
un mouvement vers l`autre agent en lui communiquant sa nouvelle position
- stop envoyé par la stratégie de contrôle
pour arrêter les traitements effectués par un agent
Le flux de messages est présenté dans la figure 3.2.4.
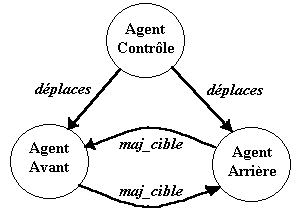
Figure 3.2.4. Le flux de messages
pour déplacer les agents
1. Agent contrôle
tant que *) les deux agents ne se sont pas rencontrés
faire
EnvoyerMsg(Agent_Avant, déplaces)
si *) les deux agents ne se sont pas rencontrés alors
EnvoyerMsg(Agent_ Arrière, déplaces)
fin si
fin tant que
EnvoyerMsg(Agent_Avant, stop)
EnvoyerMsg(Agent_ Arrière, stop)
stop
2. Agent_Avant
x = Nud(étatInitial)
y = PositionCible (But)
*) calculer h1(x,y)
répéter
msg_arrivé = Réception( )
typeMsg = TypeMsg(msg_arrivé)
si typeMsg = déplaces alors
Agent_MTS_B (h1 ,ens_opérateurs, x, y)
EnvoyerMsg(Agent_ Arrière, maj_cible, x)
fin si
si typeMsg = maj_cible alors
ActualiseCible(x, y, ValeurMsg(msg_arrivé), h1)
fin si
tant que typeMsg ¿ stop
stop
3. Agent_Arrière
x = Nud(But)
y = PositionCible(étatInitial)
*) calculer h2(x,y)
répéter
msg_arrivé = Réception( )
typeMsg = TypeMsg(msg_arrivé)
si typeMsg = déplaces alors
Agent_MTS_B (h2 ,ens_opérateurs, x, y)
EnvoyerMsg(Agent_Avant, maj_cible, x)
fin si
si typeMsg = maj_cible alors ActualiseCible(x,
y, ValeurMsg(msg_arrivé), h2)
fin si
tant que typeMsg <> stop
stop
On se remarque que les deux agents de recherche exécutent presque
le même programme, mais en utilisant des données différentes
(positions initiales, heuristiques). Pour être plus explicite on
a donné la description complète pour chaque agent de recherche
et à titre d'exercice, le lecteur pourra écrire une seule
procédure commune qui sera appelée par les agents avec des
arguments différents.
 Question.
Quelle est l`implémentation de l`algorithme de recherche bidirectionnelle
centralisée en temps réel utilisant une procédure
commune pour chaque agent de recherche ? Question.
Quelle est l`implémentation de l`algorithme de recherche bidirectionnelle
centralisée en temps réel utilisant une procédure
commune pour chaque agent de recherche ?
Pour se déplacer à la position suivante et actualiser l'heuristique
propre, les agents exécutent la procédure centrée
sur Agent_MTS _B, obtenue à partir de la procédure Agent_MTS()
présentée antérieurement, mais en effectuant une
seule itération à chaque fois qu'un message avec une commande
de mouvement arrive.
Détails de programmation: On considère que toutes
les fonctions et procédures suivantes ont comme arguments des références
(notamment h,x,y), ce qui permettra que toutes les modifications faites
à l`intérieur de la fonction sur ces variables soient transmises
à l'extérieur.
Procédure Agent_MTS_B (h ,ens_opérateurs, x, y)
est
NudSuivant = DétermineSuivant_MTS(x,y,h,ens_opérateurs)
h (x,y) = max( h(x,y), h(NudSuivant,y)+co«t(x,NudSuivant))
ExécuteMouvement (x,NudSuivant)
x = NudSuivant
Fin
Fonction DétermineSuivant_MTS(x,y, h ,ens_opérateurs)
est
hmin = VAL_MAX
pour *) chacune op dans ens_opérateurs,
avec op valide faire
s = Successeur(x,op)
*) calculer h(s,y)
si hmin > h(s,y) alors
hmin = h(s,y)
sm = s
fin si
fin pour
retourne sm
Fin
La procédure suivante est exécutée par un agent
de recherche, à la suite d`un mouvement qui a déplacé
l`autre agent, considéré comme cible pour l`agent courant.
Procédure ActualiseCible(x, y, ynouveau, h) est
*) calculer h(x,ynouveau) pour la nouvelle position de l`autre
agent (cible)
h (x,y) = max ( h(x,ynouveau)-co«t(y,ynouveau), h(x,y))
y = ynouveau
Fin
On remarque que dans le cas d'un déplacement de la cible on diminue
la valeur de h() avec coût(y,ynouveau), représentant le coût
de l'arc (y,ynouveau) le long duquel l'autre agent s'est déplacé.
On rappelle que ynouveau représente la nouvelle position de l'agent
qui s'est déplacé, position transmise par un message de
type maj_cible.
Complétude
Pour un algorithme de type RTBS découplée, basé
sur MTS, on peut prouver que si:
- l`espace d`états est fini et connexe (il existe toujours un
chemin entre chaque paire d`états),
- les valeurs initiales de l`heuristique sont non-négatives et
admissibles,
- les agents exécutent alternativement leurs mouvements et un
agent (avant ou arrière) périodiquement ne se déplace
pas
alors les deux agents peuvent finalement arriver dans un même
état.
Question.
Pourquoi est-il nécessaire qu`un agent (avant ou arrière)
ne se déplace pas de temps à temps ?
Comparaison des complexités des algorithmes RTBS centralisés
et découplés
Il est bien connu que le nombre des états développés
influence la complexité en place mémoire et que le nombre
des mouvements effectués par les agents détermine la complexité
en temps. On observe que :
- dans l`algorithme RTBS centralisé on effectue un nombre de
mouvements plus petit parce qu`on dispose de plus d`information que
dans la variante découplée ;
- dans l'algorithme RTBS centralisé le nombre des états
développés pour chaque mouvement est le double de celui
de la variante découplée, parce que le nombre des états
développés est égal à la somme des nombres
des états développés par chaque agent de recherche.
Si on compare les deux variantes de RTBS, centralisée et découplée,
avec un algorithme de recherche en temps réel unidirectionnelle
(Real Time Unidirectional Search - RTUS), on va trouver que le co«t par
état visité en RTBS est à peu près deux fois
plus grand celui de RTUS. Ce co«t élevé est obtenu parce
qu`en RTBS centralisée le nombre d`états traité est
deux fois que dans RTUS et dans la variante découplée le
nombre de mises à jour des valeurs de l`heuristique est double.
Question.
Quelles sont les mises à jour effectuées en RTBS découplée
pour chaque déplacement ?
Les expérimentations présentées dans la littérature
qui ont été effectués sur des divers problèmes
et variantes des topographies heuristiques ont montré que les performances
de RTBS dans des situations statiques et dynamiques, dépend bien
de la topographie de l`heuristique utilisée pour résoudre
le problème concret. Quand le nombre d`états existant dans
la dépression heuristique et la capacité de la dépression
(c'est-à-dire la somme de la profondeur de tous les états
de la dépression) sont grandes, le co«t de recherche va croŸtre.
Il faut souligner aussi que dans le cas de la recherche bidirectionnelle
une erreur faite par un agent va influencer négativement les actions
de l`autre agent de recherche.
L`analyse des performances de RTBS peut offrir des solutions pour organiser
et coordonner la recherche par plusieurs agents.
Recherche Multi Agents Temps Réel (Real Time Multi Agent
Search RTMS)
Dans le cadre de cette technique plusieurs agents recherchent en temps
réel, donc en se déplaÓant physiquement, un but appartenant
au même ensemble d`états but. La recherche se termine quand
un agent arrive dans un état but.
Les agents mettent en commun les valeurs heuristiques, mais agissent
indépendamment.
Le problème est complet et la solution est atteinte plus rapidement
que dans la recherche uni ou bidirectionnelle.
|
